-
[딥러닝 #1] 딥러닝의 기초EVI$ION/DEEP LEARNING 2019. 4. 1. 06:03
[인공지능과 머신러닝, 딥러닝의 차이]
인공지능: 인간과 유사한 사고 구조를 컴퓨터로 구현한 기술이다.
머신러닝: 기계를 학습시킴으로써 인공지능의 성능을 보다 향상시킨 기술이다. 사람이 직접 필요한 데이터를 넣으면, 기계는 이를 학습하여 인간보다 더 정확하고 올바른 결과를 도출해낸다.
딥러닝: 머신러닝과 유사하지만, 머신러닝처럼 사람이 데이터를 선정해 학습시킬 필요가 없이 아무 데이터나 넣어도 기계 스스로가 학습하여 필요한 특성을 찾아나가는 기술이다.

[딥러닝이 데이터를 처리하는 방식, 신경망(Neural Network)]
딥러닝은 인간의 뉴런과 비슷한 인공신경망(Artificial Neural Network, ANN) 방식으로 정보를 처리한다. 따라서 이 신경망을 학습시키는 것이 딥러닝의 핵심이다.
그렇다면 신경망은 대체 무엇인지 예시를 통해 알아보자.
집값을 결정하는 요인에는 평수, 방의 개수, 주변 환경 등 여러 가지가 있다. 집값을 y라 하고 집값을 결정하는 요인(특성) 중 하나를 x1이라 하자. 그렇다면 x1에 의해 결정된 y의 데이터가 여러 개 쌓이면, 어떤 함수를 도출해낼 수 있을 것이다. 이 함수를 노드(node)라고 하고, x1이 노드를 거쳐서 y가 되는 일련의 과정(x1 → node → y)을 뉴런(neuron)이라 한다.

뉴런(neuron) 노드는 선형 함수일 수도 있고 비선형 함수일 수도 있지만, 보통 신경망에서 많이 보이는 형태는 선형 회귀곡선 중 하나인 ReLU(Rectified Linear Unit) 함수 형태이다. ReLu의 Rectify는 결과값과 0 중 큰 값을 취하라는 의미로, 뉴런은 입력받은 x1으로 선형 함수를 계산한 결과값과 0 중 큰 값을 집값 y로 예측한다.

x1과 y 사이의 선형 회귀 곡선 
ReLU(Rectified Linear Unit) 함수 x2, x3, x4...도 x1과 같은 방법으로 뉴런을 생성하고, 이 뉴런들이 쌓이면 신경망이 형성된다. 입력되는 데이터의 양은 많을수록 좋은데, 해당 뉴런과 관계없는 데이터도 입력으로 넣어주면 신경망은 학습을 통해 관계 여부를 알아서 조정한다.
결과적으로 신경망이란 x와 y 사이의 관계를 나타내는 함수를 찾는 과정이다.

은닉층(hidden layer)이 2개인 신경망(Neural Network) [데이터의 종류]
구조적 데이터 (Structured Data)
- 데이터베이스로 표현된 데이터, 즉 MySQL과 같은 관계형 DB에 들어갈 수 있는 데이터를 말한다.
- 각 데이터마다 column과 row가 존재한다.
비구조적 데이터 (Unstructured Data)
- 이미지, 오디오, 텍스트 등 데이터베이스로 표현되지 않은 데이터를 말한다.
- 이미지의 픽셀값, 텍스트의 각 단어들 등이 데이터의 특성이 된다.
[머신러닝 학습의 종류]
지도 학습 (Supervised Learning)
- 데이터에 대한 레이블을 주어 컴퓨터를 학습시키는 방법이다.
- 레이블(Lable)은이란 명시적인 정답을 의미한다.
- (데이터, 레이블) = (x, y)
비지도 학습 (Non-Supervised Learning)
- 지도 학습과는 반대로, 정답(레이블)이 주어지지 않고 데이터를 비슷한 특성끼리 그룹으로 묶어 분류하는 학습 방법이다. (ex. Clustering 알고리즘)
- 숨겨진 특성이나 구조를 발견하는 데에 사용된다.
강화 학습 (Reinforcement Learning)
- 에이전트가 주어진 환경에서 행동을 하고 그에 대한 보상을 얻으며 학습을 진행하는 방법이다.
▶ 기존 컴퓨터는 구조적 데이터는 쉽게 이해했지만 비구조적 데이터는 제대로 인식하지 못했다. 그러나 딥러닝과 신경망의 등장으로 인해 컴퓨터는 비구조적 데이터까지도 잘 이해할 수 있게 되었고, 이에 따라 이미지 인식, 음성 인식, 자연어 처리(Natural Language Processing, NLP) 등의 구현이 가능해졌다.
[딥러닝이 이제서야 뜬 이유]
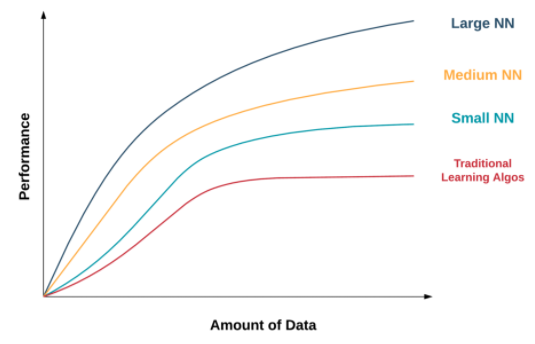
데이터의 양과 성능의 상관관계 딥러닝의 성능은 데이터의 양과 신경망의 규모에 비례한다.
여기서 말하는 데이터는 레이블이 있는 데이터를 의미하고, 데이터의 양은 입력값 x와 레이블 y가 같이 있는 훈련 세트의 크기, 즉 (x, y)의 개수를 말한다. 훈련 세트의 크기가 작을 때에는 구현 방법에 따라 딥러닝의 성능이 결정된다.
과거에는 데이터의 양이 한정적이었고, 데이터를 최대한 많이 모아 신경망의 규모를 증가시켜도 그 규모의 신경망을 빠르게 훈련시킬만한 CPU가 갖춰지지 않았기 때문에 발전이 어려웠다.
그러나 기술이 발전함에 따라 데이터의 양이 많아지고, CPU와 GPU의 발전으로 데이터의 처리 속도가 증가했으며, 신경망을 더 빠르게 실행시키는 알고리즘들이 많이 개발됨으로써 딥러닝이 본격적으로 활용되기 시작했다.
[신경망 활성화 함수]
ReLU(Rectified Linear Unit) 함수 위에서 노드는 함수로 이루어져 있고, 특히 ReLU 함수가 많이 사용된다고 설명했었다. 이 ReLU 함수는 활성화 함수의 한 종류이다.
활성화 함수란, 개별 뉴런에 들어오는 입력 신호의 총합을 출력 신호로 변환해주는 함수이다. 활성화 함수로는 대부분 비선형 함수를 사용하며, 대표적으로 시그모이드(Sigmoid) 함수가 있다.

시그모이드(Sigmoid) 함수 시그모이드 함수는 입력 신호의 총합을 0에서 1 사이의 값으로 변환해주는 함수이다. 입력 신호의 값이 커질수록 1에 수렴하고, 입력 신호의 값이 작아질수록 0에 수렴한다.
[이진 분류 (Binary Classification)]
입력값에 대한 분류 결과가 참(1) 또는 거짓(0) 두 가지만 있는 분류 모델이다.
[로지스틱 회귀 (Logistic Regression)]
로지스틱 회귀란, 확률 모델로서 독립 변수의 선형 결합을 이용해 사건의 발생 가능성을 예측하는데 사용되는 통계 기법이다. 지도 학습에서 레이블이 0 또는 1인 경우, 즉 이진 분류인 경우에 사용된다. 기본적으로 시그모이드 함수의 형태를 지닌다.
[참고 문헌]
https://korea7030.github.io/Study1/
https://medium.com/mighty-data-science-
https://ratsgo.github.io/deep%20learning/2017/04/22/NNtricks/
https://excelsior-cjh.tistory.com/177
[이미지 출처]
http://www.realinite.co.jp/article/ai/article5/index.php?language=en
https://sungjk.github.io/2017/04/26/Ch5-deep-learning.html
'EVI$ION > DEEP LEARNING' 카테고리의 다른 글
[딥러닝 #3] 백터화된 로지스틱 회귀/경사하강법, 인공신경망 (0) 2019.05.06